今年我 SITCON 有投一篇微服務的議程:「選課卡成狗?微服務架構帶你翻轉校園系統」。在 SITCON 之前,我打算每天在 Blog 上寫一篇和 Cloud Native 相關的短文,來當作議程的前導內容。當然針對每一篇短文的意見回饋(看不懂也是一種意見反饋 🥺),最終都有助於我產出更好的議程內容~
這個系列的第二個主題,還是延續我們上次的選課系統設計。昨天我們發現到單體的方式開始造成資源的浪費以及資料庫的瓶頸,所以我們或許可以看看怎麼把選課系統拆成雲端原生的微服務架構。
考慮到 Blog 本身不是一個很好的互動平台,我在每篇文章的底下都會留「💬 互動區塊」,連結到和這篇文章相關的社交媒體上。你可以在社交媒體上和這篇文章互動~
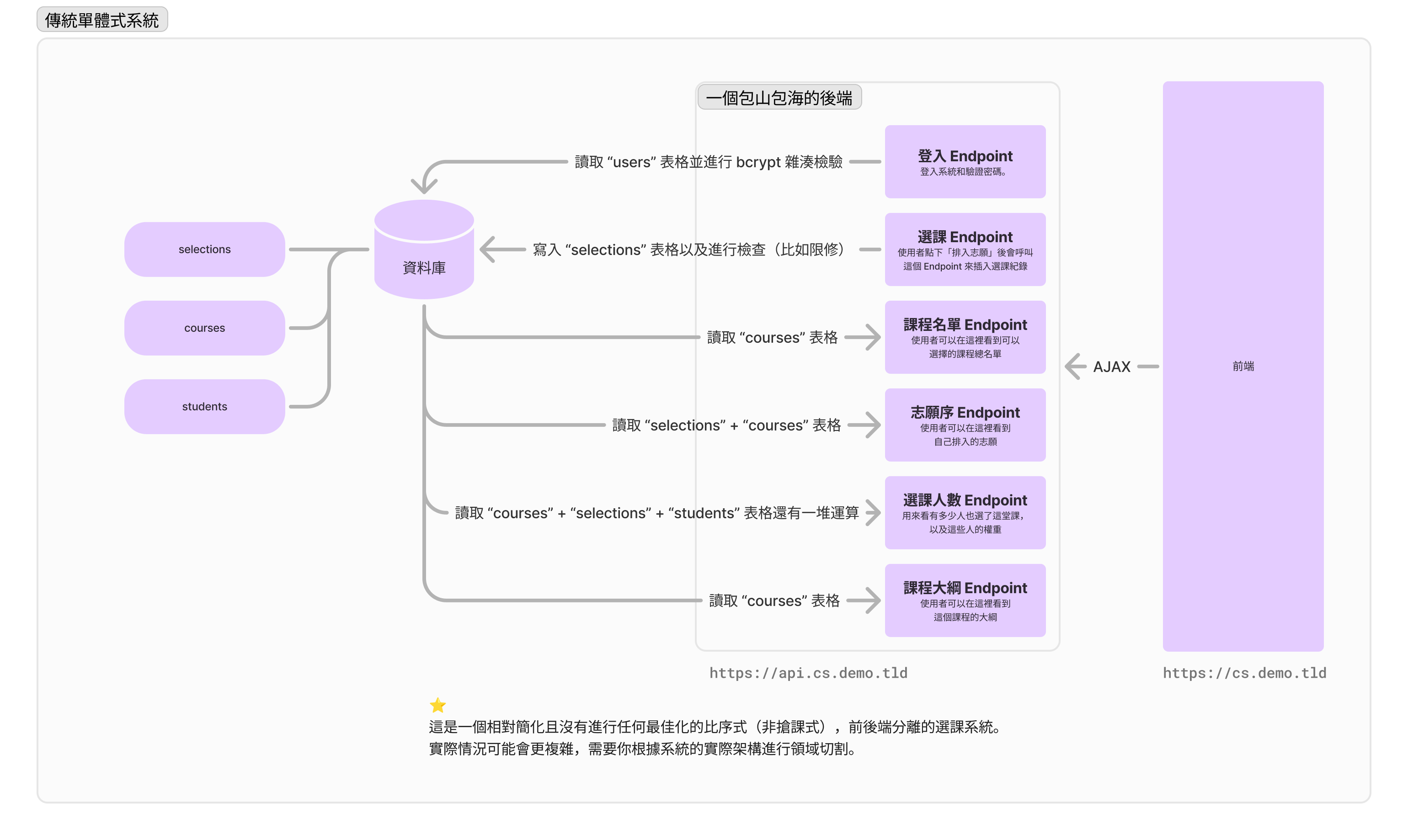
怎麼將單體服務拆分成微服務?
或許你會疑惑「微服務」是什麼。首先就「服務」這個詞來說,後端是個服務,前端也是個服務,基本上任何能提供 API 進行呼叫的都是服務。「微服務」本質上就是把我們的後端拆得更細緻:比如說我們可以把使用者相關的東西變成一個服務、把課程相關的東西變成一個服務、把志願序變成一個服務等等。
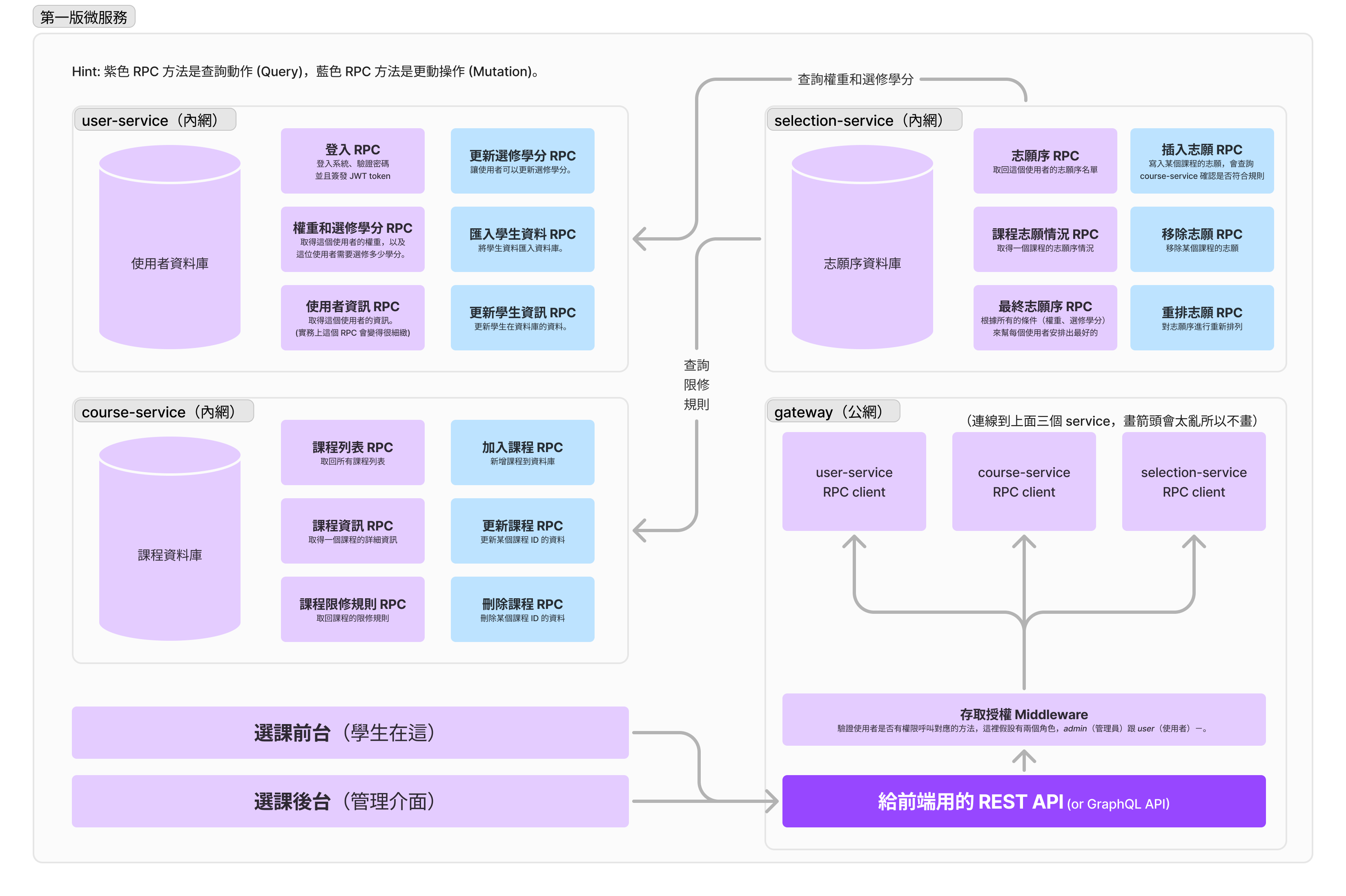
我們通常會把每個服務管轄的部分稱之為「領域」,只有這個區域內的服務可以直接操縱資料庫的資料,而不在這個區域的只能透過 RPC(遠端程序呼叫,比面向用戶端的 REST API 相對隨便,主要供內部使用的 API)撈資料。你可能會想「領域是不是就是資料表的名稱?」,但實際上其實不止於此,粒度通常會大得多,通常會追求「服務(的領域)可以獨立運作」。我們把以「領域」進行思考的一套模式叫做 DDD(領域驅動開發),實際展開的篇幅會相當長,這裡就不對拆服務和 DDD 多做說明(實際上你也不一定要學會 DDD 才能用微服務,靠經驗拆也是可以的!)
就以上面的例子來說,我自己認為使用者服務(user-service)、課程資訊服務(course-service)和選課服務(selection-service)是三個領域上可以獨立運作的服務——換言之,假如使用者服務掛掉,我預期我還能看課程資訊以及改動志願序;假如選課服務掛掉,我一樣可以更新我的選修學分。不過你應該也有發現到「選課服務」相對複雜一點,因為插入志願和最終志願序需要做很多判斷邏輯,需要連線到使用者服務看權重,以及連線到課程服務查詢限修規則,這時我們可能需要處理選課服務在其他兩個服務掛掉時的處理邏輯。但撇除掉這兩個 RPC 方法,服務大體上還是可以獨立運作的。
【🤔 想想看!】你覺得上面的微服務架構,是不是一個好的拆法?
微服務的水平擴縮 (scaling)
接著回答昨天的問題:我們這樣開發出的服務,可以怎麼降低資料庫的壓力,以及怎麼針對性的對服務進行擴充來分散壓力?首先,從上圖其實就能很明顯看到「我們把每個領域對應的資料庫都拆出去了,」換句話說,每個資料庫只需要負責自己領域內的事情(使用者資訊、課程資訊、選課資訊),壓力自然就比單體的「包山包海」小上很多。接著,其實每個微服務都應該可以水平擴縮 (scaling),所以你可以規劃「志願序服務的壓力比較大,所以我們可以開多一點服務來平衡」;「使用者服務幾乎不怎麼需要讀取,所以我們可以就開少少的機器就好」:
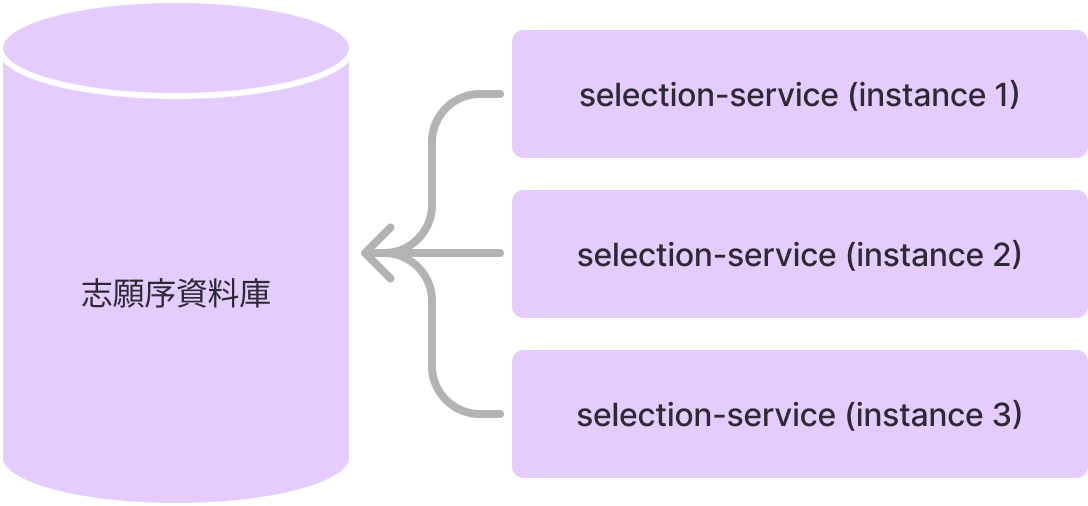
接下來我們也會講到很多微服務上的設計技巧,來發揮微服務更大的作用——比如快取。
【🤔 想想看!】我們要怎麼把請求分散到上面說的這三個微服務呢?是不是所有微服務都必須共用一套狀態(資料庫)?共用的缺點是什麼,以及快取區需要共用嗎?
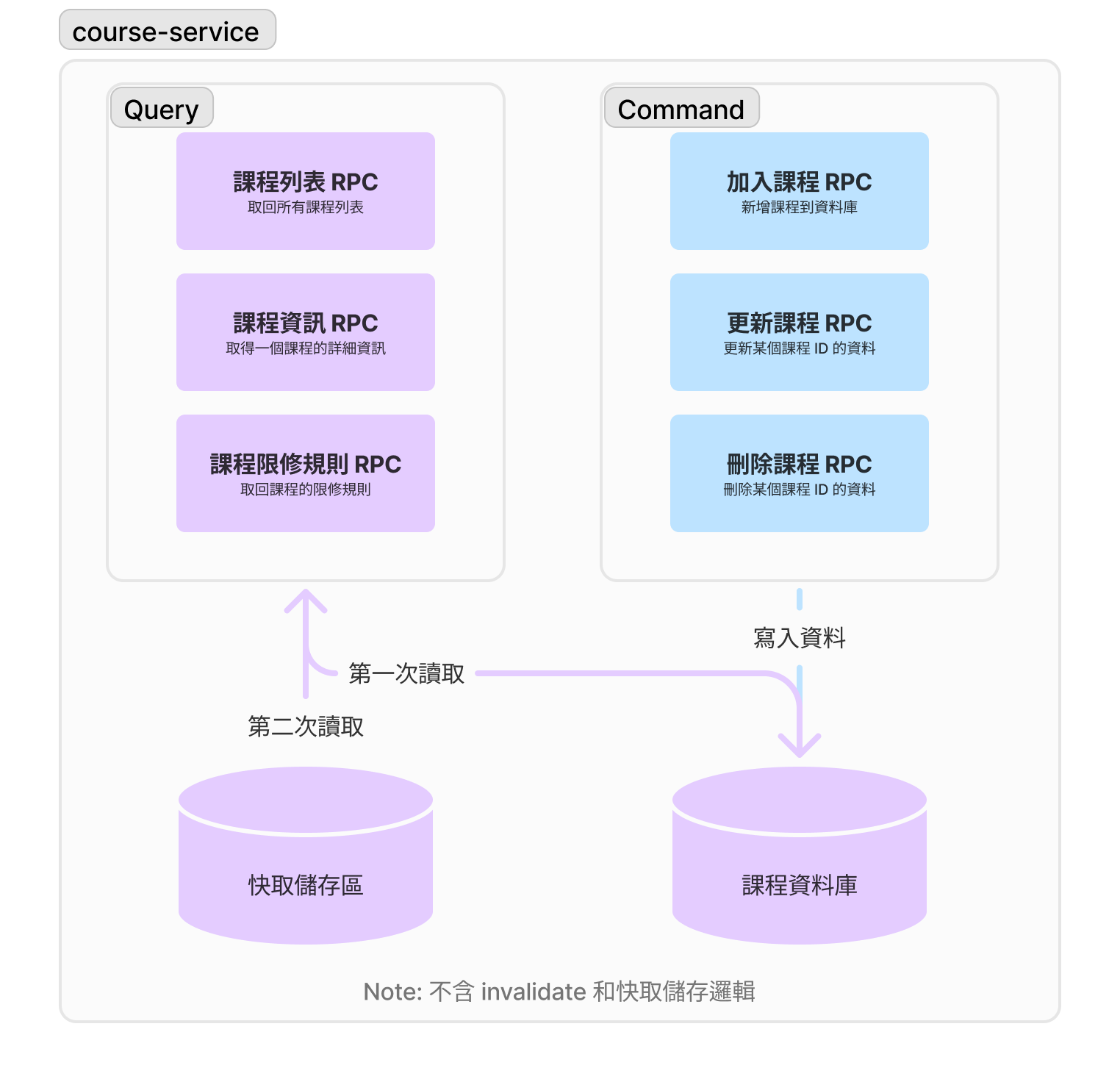
查詢與更動分離 (CQRS)
你接著還會疑惑「查詢動作跟更動動作」差在哪裡。舉個例子,為什麼我們沒有選擇加一個「插入志願之後列出學生志願序」的查詢 + 更動 RPC,而是選擇分開變成「插入志願 RPC」+「志願序 RPC」呢?其實這種叫 CQRS,把「查詢」跟「更動(命令)」分開的一種設計模式。
為什麼我們要分開查詢(讀取)跟更動(寫入)呢?通常讀取動作不用擔心狀態問題,也就是說「就算我今天讀取 1000 次同一筆資料,只要沒有改動,得到的結果應該都要是一樣的」;寫入操作的狀態問題就複雜得多,執行順序、重複插入就足以造成大影響。所以:
- 讀取動作我們可以快取、可以在唯讀的資料庫 replica 實例讀取(對,很多資料庫系統是可以建立出很多個跟隨主要資料庫的唯讀 replica 實例的,通常我們叫這種功能為複寫 – replication)
- 寫入操作只能在主要資料庫進行操作,並且通常是不能快取的,相對來講效能改進的彈性會小一些。
在我們知道讀取和寫入兩個的複雜度不同後,CQRS 的設計就變得合理多了。就以「課程資料庫」來說,我們可以這樣規劃查詢和寫入:
- 課程因為幾乎不怎麼變動(讀取 > 寫入),我們可以把所有課程相關的讀取結果放到很快速的鍵值儲存區中(比如 Redis),這樣子就算你需要請求 10,000 次同個課程的資訊,我都能很快速的把資料回傳給你(而盡量不去往開銷較大的資料庫讀取)。
- 如果課程被更動了,我除了更新資料庫的內容外,也會把鍵值資料庫中對應這個課程的快取清理 (invalidate) 掉。下次讀取課程時,我們可以再去往快取區寫入新的課程資訊。
Gateway 是什麼?
我們在把系統用微服務思維重構的同時,順帶也成功對快取以及資料庫的拆分進行了很不錯的規劃。但是你會發現到上面微服務中有一小塊一直都沒提到:“Gateway” 裡面那一堆是什麼?以及,為什麼其他微服務裡面沒有任何檢查使用者憑證的邏輯?這些問題,我們留到明天再來深入研究。
【🤔 想想看!】用 CQRS 拆出的 RPC 方法,還有哪些改進效能的手段?針對「讀 = 寫」、「讀 < 寫」的情況下,快取依然還是個好方案嗎?