今年我 SITCON 有投一篇微服務的議程:「選課卡成狗?微服務架構帶你翻轉校園系統」。在 SITCON 之前,我打算每天在 Blog 上寫一篇和 Cloud Native 相關的短文,來當作議程的前導內容。當然針對每一篇短文的意見回饋(看不懂也是一種意見反饋 🥺),最終都有助於我產出更好的議程內容~
這個 Tag 的第四個主題是「服務探索」。從這個主題開始,我們要開始探討前三章說的微服務架構會有什麼問題,以及可以怎麼克服了。
考慮到 Blog 本身不是一個很好的互動平台,我在每篇文章的底下都會留「💬 互動區塊」,連結到和這篇文章相關的社交媒體上。你可以在社交媒體上和這篇文章互動~
同台機器上,服務如何互相連線?
前文的結尾我有留一個問題:「如何讓服務之間可以互相連線?」你或許會覺得這問題非常基本,因此我們不妨拿之前的微服務架構模擬看看。假如你在本機端而且不想配置網路的話,最直接的做法可能是每個服務都開不同的 port,讓 Gateway 直接用 port 連線。比如說你把使用者服務安排在 port 3001、把選課服務安排在 port 3002,然後 Gateway 用 localhost:3001 連線使用者服務、用 localhost:3002 連線選課服務;selection-service 也是用 localhost:3001 連線使用者服務、用 localhost:3002 連線選課服務。
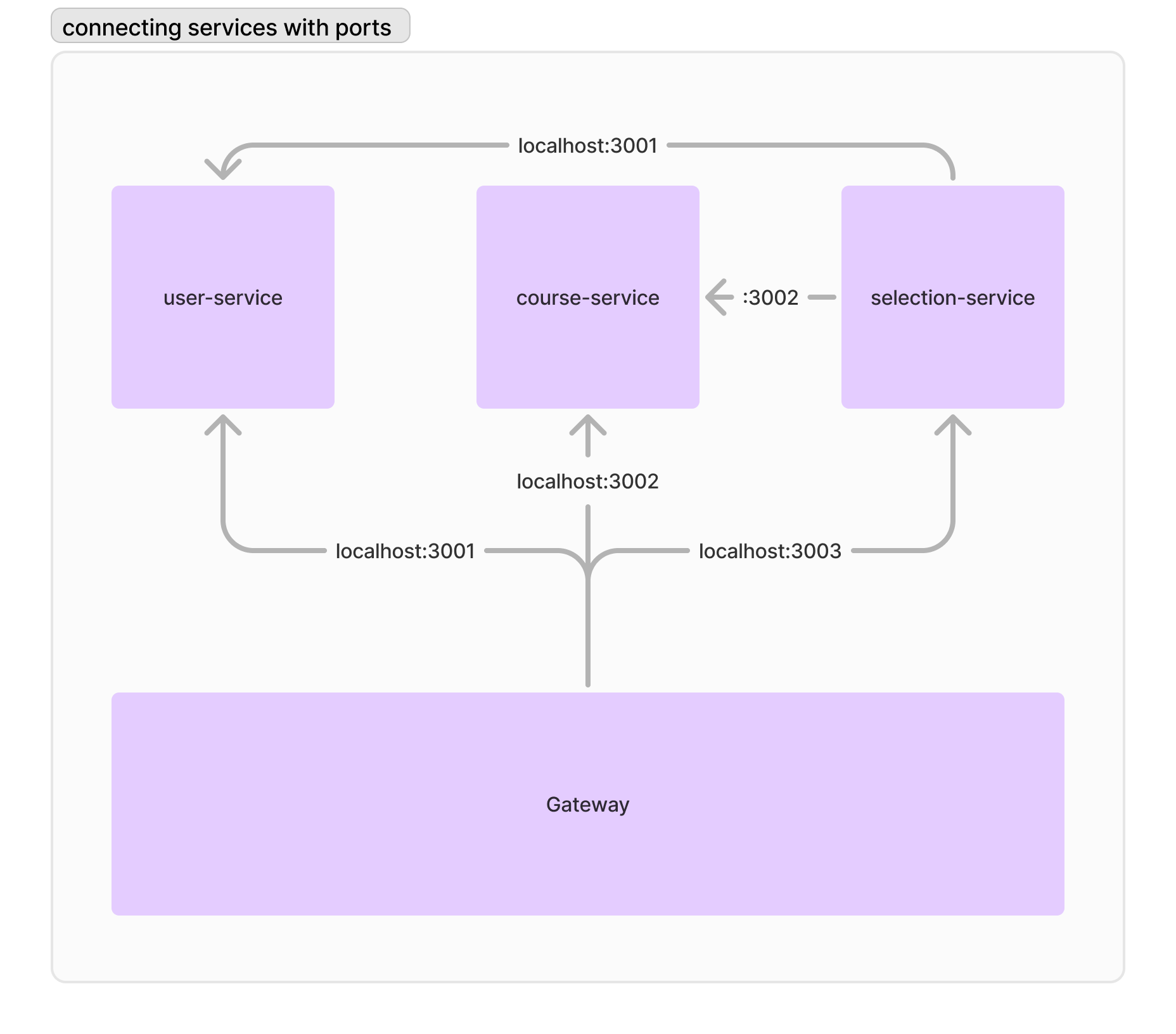
事實上假如你只在一台機器上運作的話,這種方法真的沒有什麼問題,甚至可以說是行之有年了。
多台機器上,服務如何互相連線?
不過假如我們進入到分散式的世界:把這堆服務打散到各個機器上,這樣的做法會碰到什麼問題呢?我們在第一章有分析出選課相關的功能相對耗資源,所以我們把「選課系統」獨立到不同的機器(這裡叫他機器 2)上。首先不同機器肯定會有不同的 IP,所以「機器 1」要連線到「選課服務」,肯定就不能用 localhost 連線了,我們肯定是要用「機器 2」的 IP 搭配上之前設定的 port 進行連線,也就是下面這張圖。
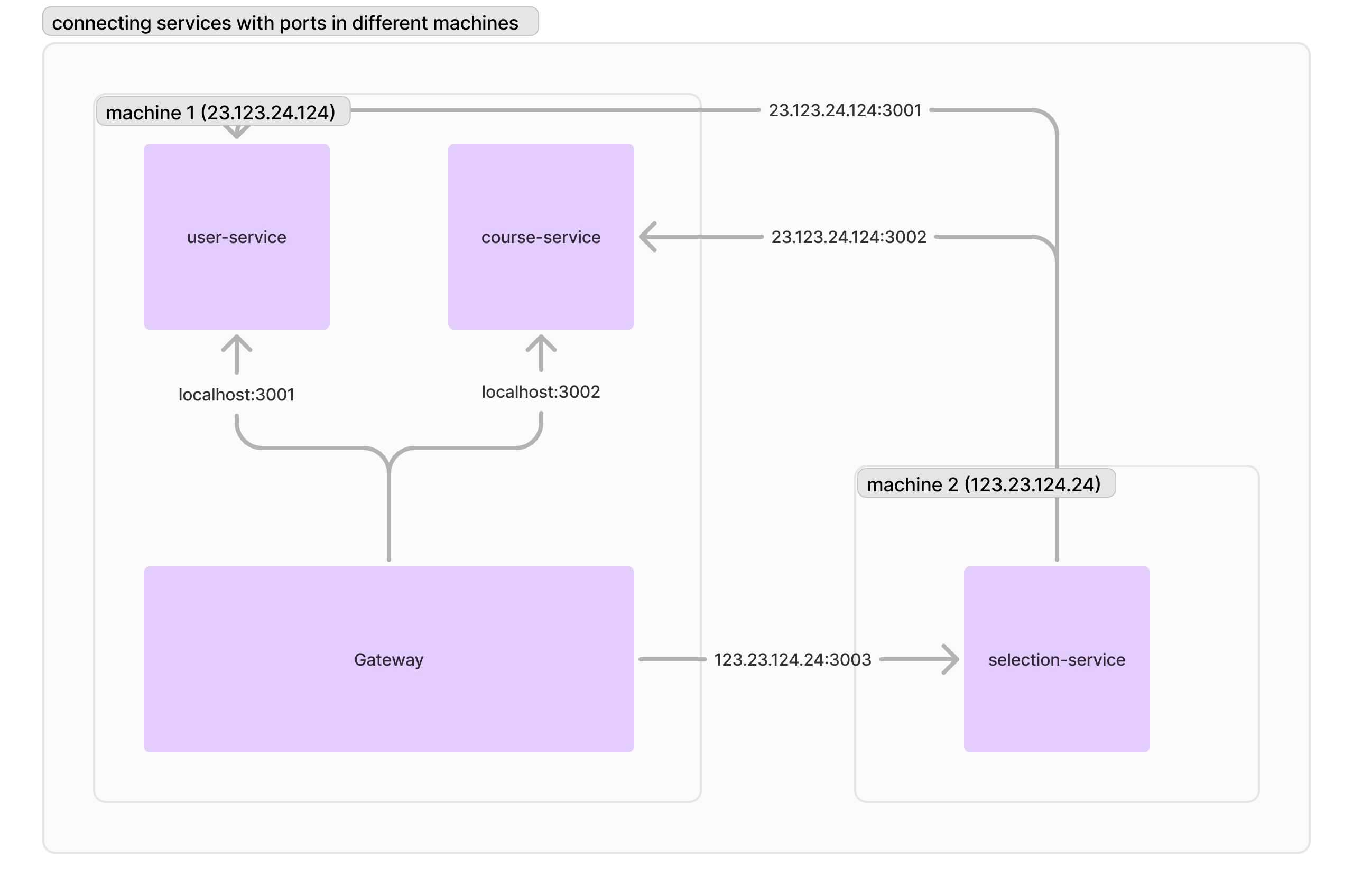
問題來了:IP 是永恆不變的嗎?機器的 IP 可能會因為區域變動(比如從新北機房移到高雄機房)而變化,我們也不一定能保證「選課服務」一定只在機器 2 上面。甚至說假如其他服務也開始有壓力,我們想要把它分出機器 1,我們也同樣需要關心到 IP 地址的議題。既然 IP 不是永恆不變的,我們就要關心起「如果 IP 改動時,會發生什麼樣的事情。」試想一下,我們把「選課服務」的 IP 換掉,我們需要改掉多少個服務連線位址呢?
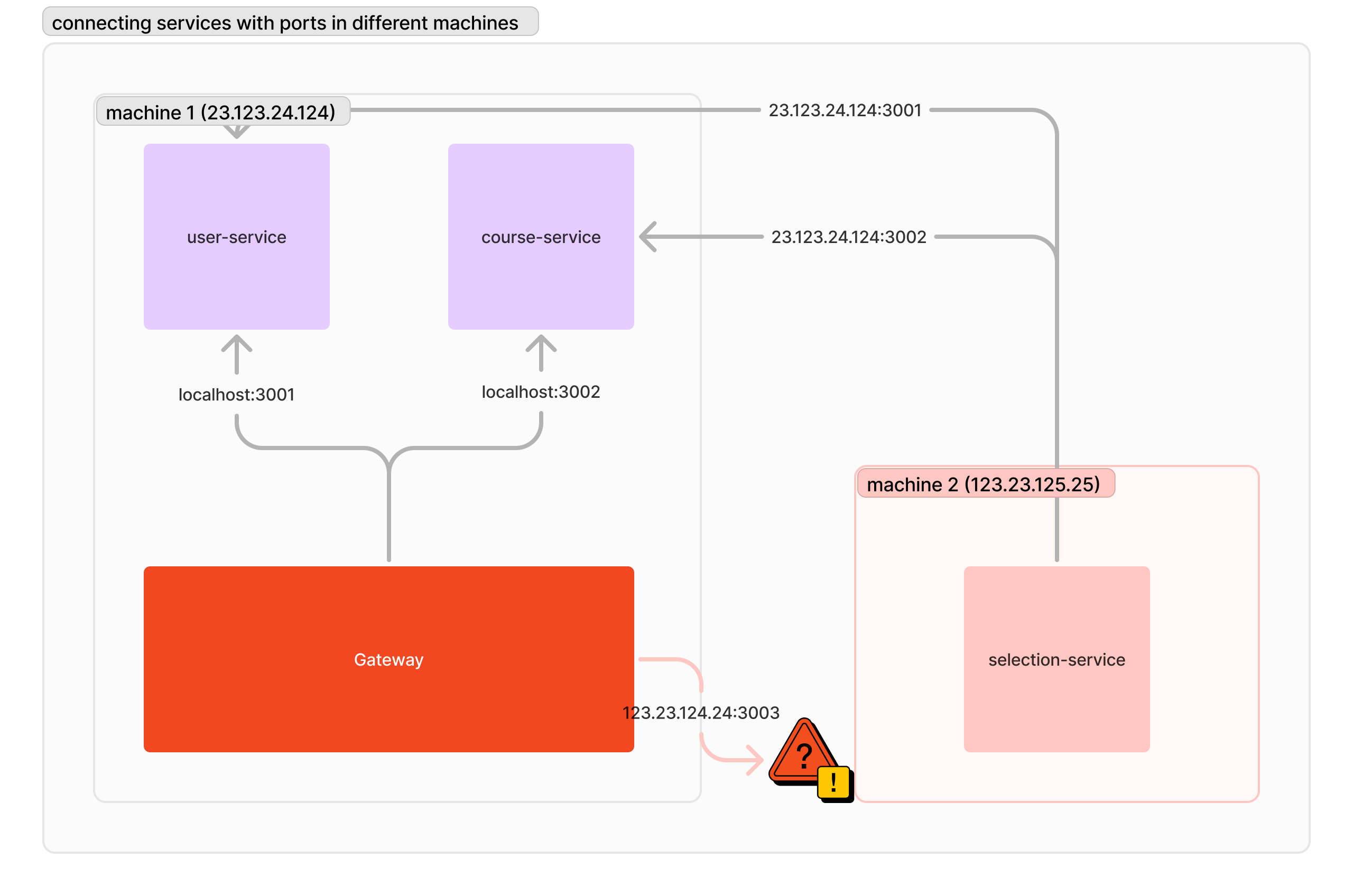
就以此例來說,你需要把 Gateway 連線「選課服務」的網址改掉。接著我們再來做一個依賴點比較多的服務改動:把「課程服務」移到其他機器上。這時候就有兩個需要「課程服務」的服務需要改掉服務連線位址了。
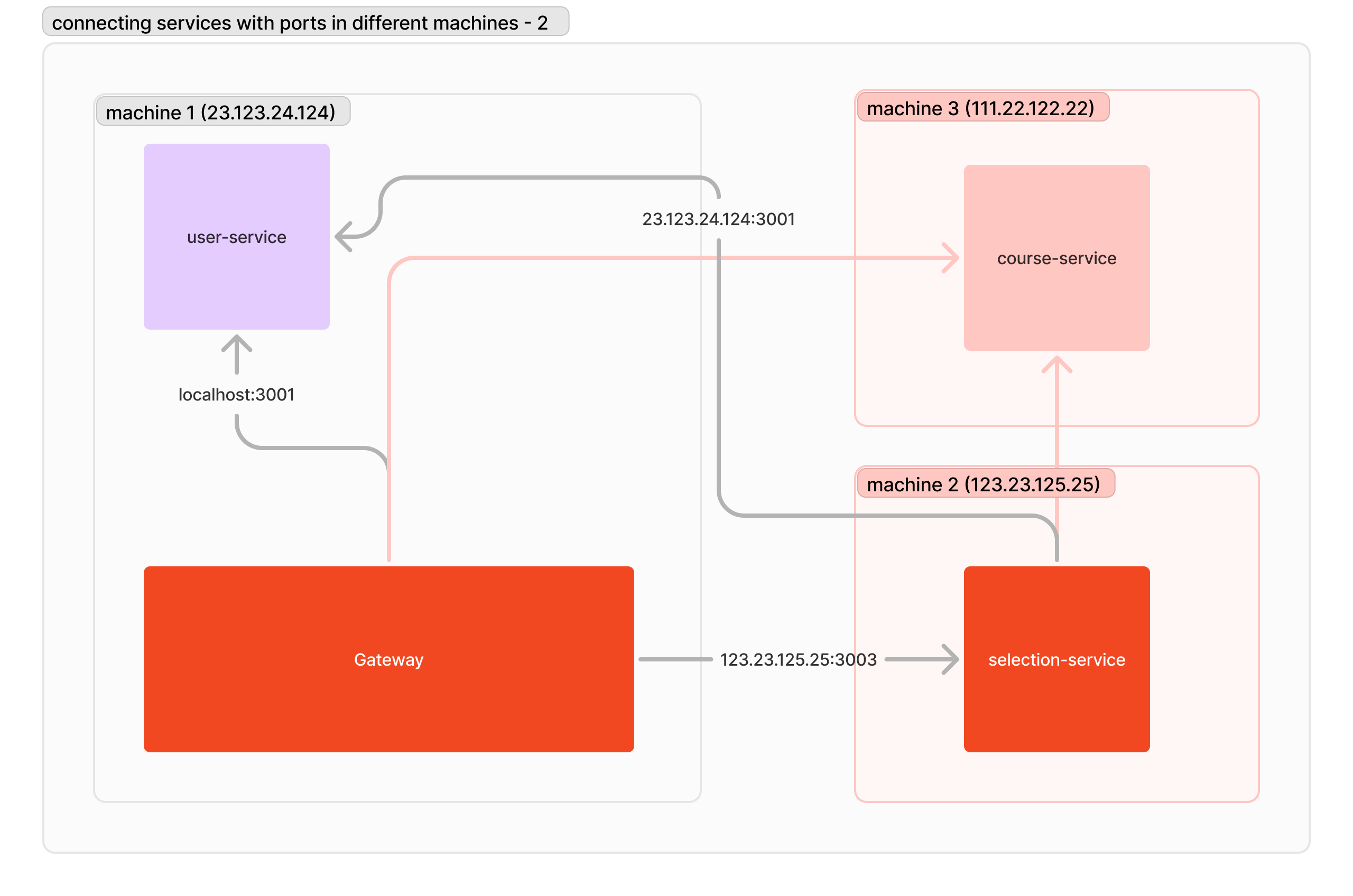
用戶端的服務探索機制
當你的服務愈來愈多、依賴關係愈來愈複雜的時候,配置服務連線位址就會變得愈來愈複雜。此時,你會想到一個很棒的解決方案:我們可不可以維護一個中央的註冊中心,來維護每個服務的地址?所以我設計了一個 registry 資料庫,假如 Gateway 要呼叫選課服務,我就先去 registry 查一下選課服務的網址,查到之後直接呼叫。這樣子的好處顯而易見,我如果要更新選課服務所在的機器,我直接更新 registry 表格,其他服務就可以自動連線到正確的地方,不需要每個服務手動設定了。
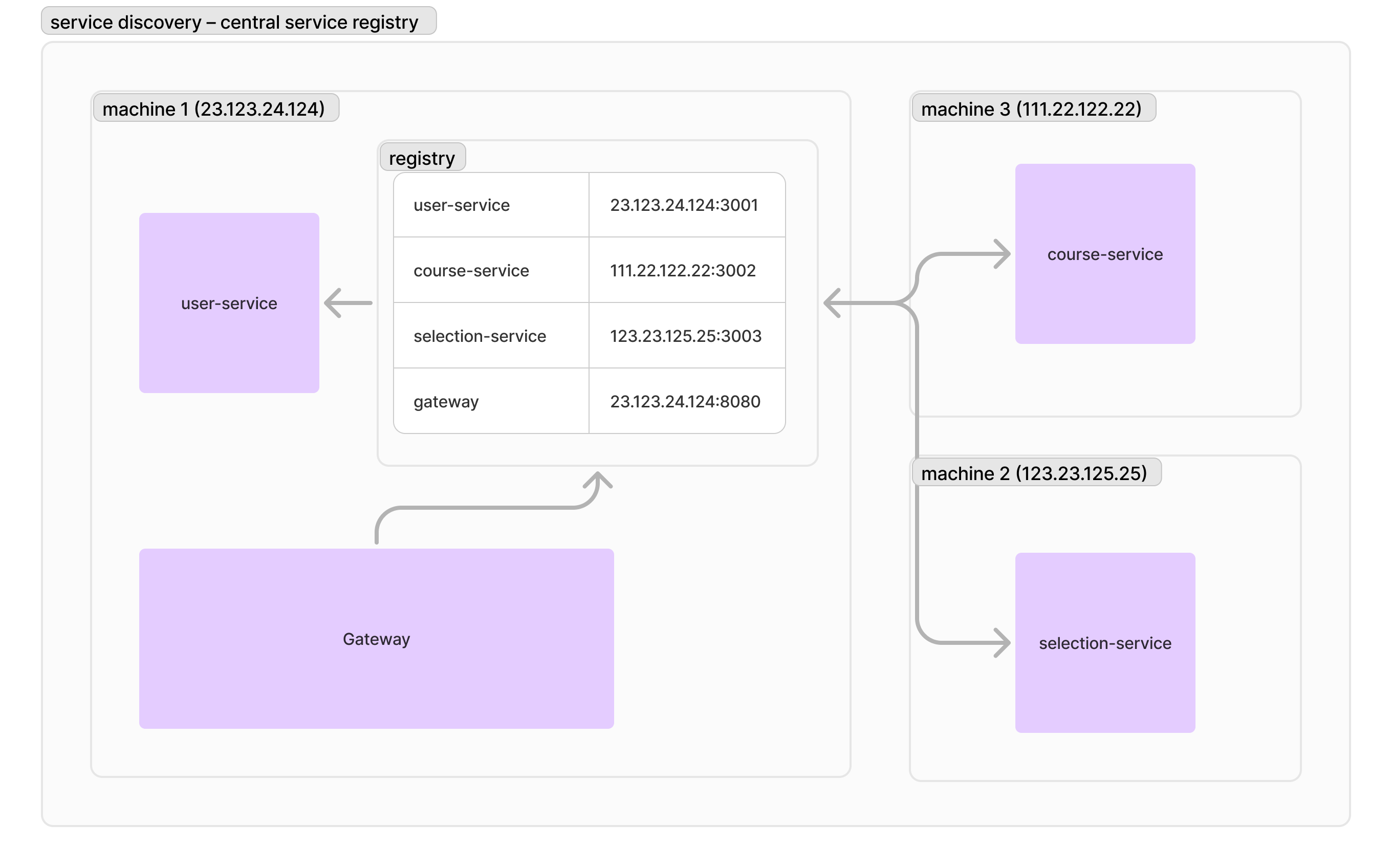
恭喜你發明了用戶端的服務探索機制 (client-side service discovery)!這種 registry 基本上可以是任何可以分散式存取的鍵值資料庫,不過通常更多人會選擇已經封裝好的解決方案,比如 https://www.consul.io/。關於 Consul 的具體用法這裡就不展開,我們接著來說說下個問題。
伺服器端的服務探索機制
眼尖的你應該有發現到兩個問題:首先,假如機器 1 上的 registry 掛掉,其他服務是不是就沒法互相溝通了呢——也就是「單點故障」呢?所以,我們實務上通常會在所有機器上開 registry,然後讓 registry 互相同步 (replication)。Consul 通常已經內建好同步方案了,你只需要配置好主從節點就好。
🤔 除了整合方案 (Consul) 外,還有什麼鍵值資料庫可以高效地做到主從複寫 (replication)?
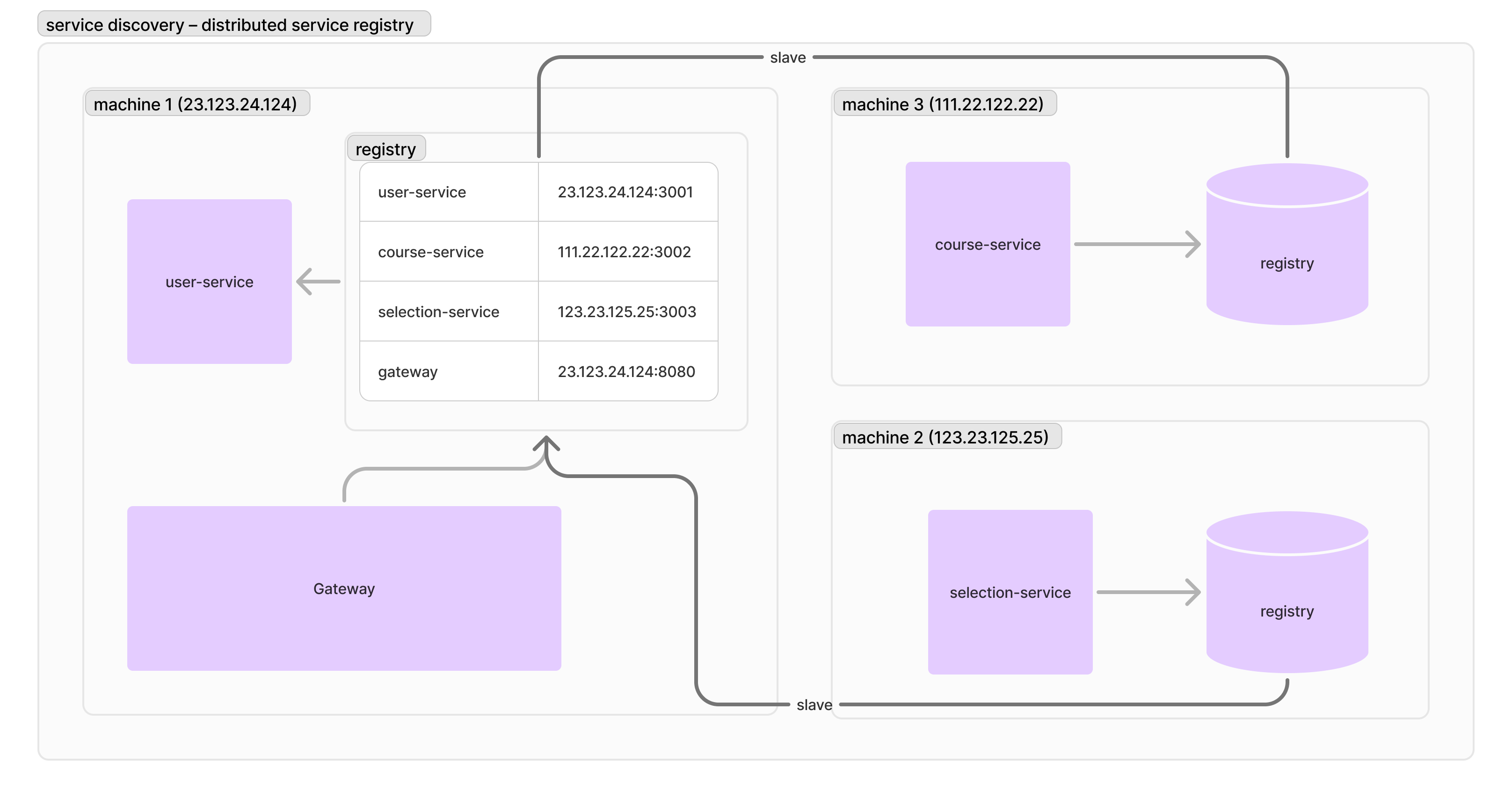
第二個問題,是「我們一定要引入一個服務來做這件事情嗎?」為了服務探索,我們除了需要引入鍵值資料庫,還需要在所有服務中加入連線到 registry 以及找出對應服務的 IP 的方法。在新專案上可能不成問題,但在老專案或者是比較不常見的技術堆疊下(比如 Rust 就沒有官方的 Consul SDK),可能就會變得非常複雜。我們可不可以利用基礎建設提供的功能來做呢?
假如你用 Kubernetes(或 Docker Swarm)的話,你或許會看過一種做法:給「使用者服務」、「課程服務」、「選課服務」各建立一個 Service,互相用 DNS(比如 course-service 這樣的網址)進行連線。其實這也是一種服務探索,但因為是 Kubernetes 負責管理可用的連線,所以會歸類在伺服器端的服務探索 (server-side service discovery)。
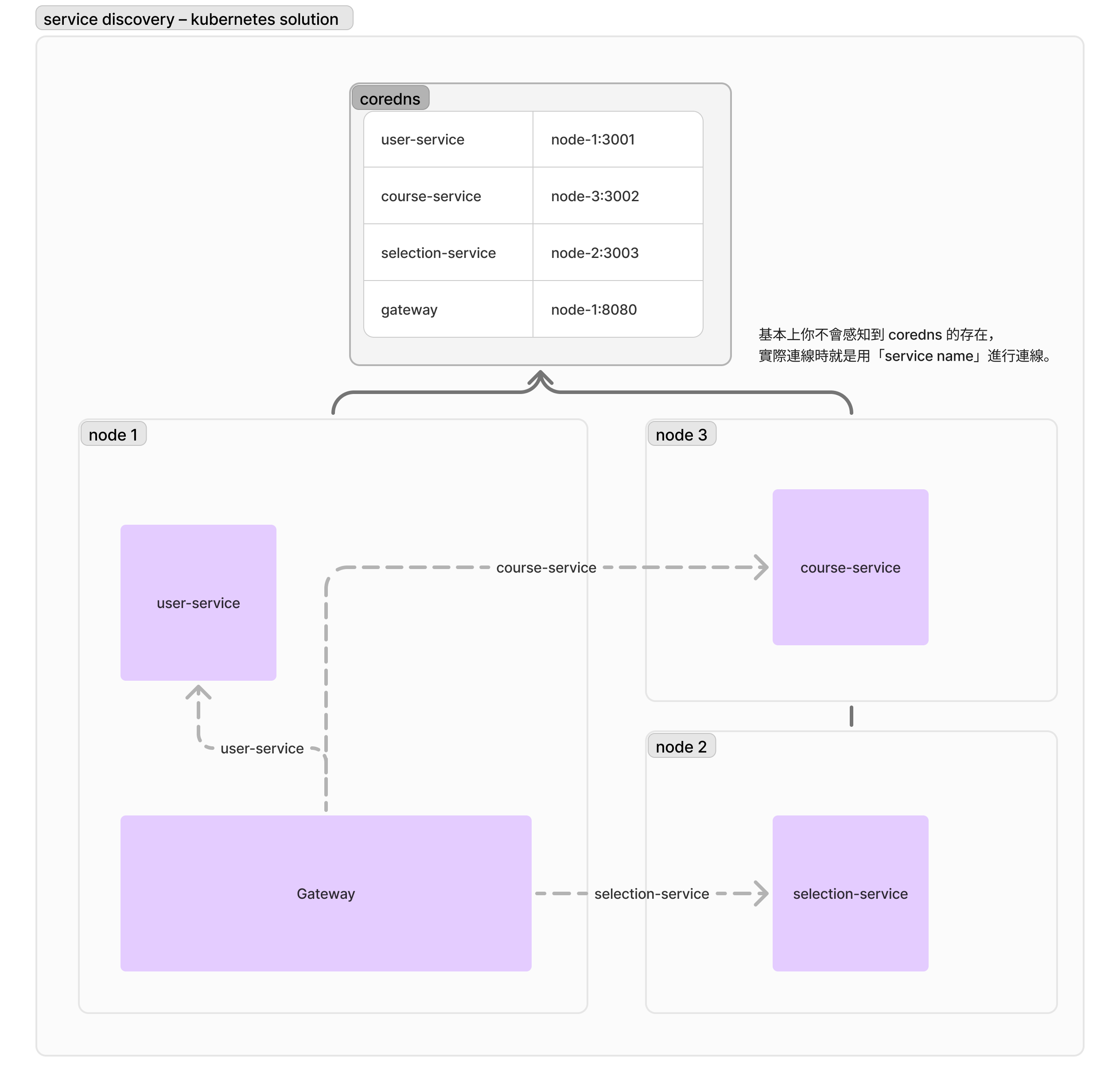
📚 Kubernetes 的節點(Node)可以粗略地理解成「機器」,是個更通用的說法。我們後續的文章也會盡量用節點,代替「機器」這個比較不專業的名詞。
關於 Kubernetes 的 Service 是怎麼讓每個服務都知道對方服務的 DNS name 的,這部分也是不會多做詳細說明。不過這樣子有個好處:你終於不需要引入任何額外套件來做服務探索了,你只需要一個會讀系統 DNS 設定的用戶端,就能用 selection-service 這種很直覺的名稱連線到需要的服務了。
🤔 你有猜出 Kubernetes Service 做伺服器端服務探索的原理了嗎?
怎麼擴縮服務⋯⋯?
到這裡服務探索其實就告一段落了——你已經知道有兩種方案可以辦到服務探索了,一個是以 Consul 為代表的由用戶端探索,另一個是以 Kubernetes 的 DNS 為代表的由伺服器端探索。不過你應該發現到一個問題:我們微服務一直強調的點就是「擴縮」(scaling),但是這裡講的「服務探索」似乎沒有提到任何「服務的水平擴縮」,我們好像都是連線到不同節點的 單一個 服務上——這樣子和單體服務似乎就沒什麼兩樣了,如果一個服務發生很大的負載,我們還是沒辦法很快把請求分散到其他機器。我的下一篇介紹會介紹到水平擴縮跟負載平衡的具體實作方案,剛好就可以來解決平衡請求負載的問題 😄
💬 互動區塊
WIP