背景
https://twitter.com/repsiace/status/1554103778994900992/

修改一下:work stealing, thread-per-core, waker, mpsc, task queue 只有他们懂… 正常人不可能看懂 – @twicemoemoe, 22-08-02
作為一個文組,其實覺得 async 真的沒有想像中的這麼困難 ⋯⋯ 😂 或許搭配一些圖片會好懂很多吧。
TL;DR 不廢話版本
- Sync(同步):一件事情做完之後,再做下一件事情。
- blocking(堵塞):指「等一件事情」的行為。
- Async(非同步):一件事情還沒完成,可以做其他不衝突的事情。
- concurrency(並行、併發):程式 架構 中,各個任務可以 獨立執行 的特性。
- future:Rust 中的一個非同步任務的表示。
- polling:不停地詢問任務,確認事情是否已經完成。
- event-driven:事情完成後,任務自己發通知表明完成。
- parallelism(平行):同時 執行 數個程式的行為。
- thread(執行緒、線程):系統處理程式(任務集)的基本單元。thread 通常是交由 CPU 核心執行。
- spawn(生成):指產生 thread 的行為。
- thread pool(執行緒池):將 thread 高效分配給每個任務的地方。
- thread(執行緒、線程):系統處理程式(任務集)的基本單元。thread 通常是交由 CPU 核心執行。
- concurrency(並行、併發):程式 架構 中,各個任務可以 獨立執行 的特性。
- Async runtime: 以 tokio 為例
- join (macro):並行執行 async 函數,並在全部完成後回傳。
- select (macro):哪個 async 函數快,回傳那個 async 函數的結果。
- main (attribute macro):在 main() 初始化 runtime。
- block_on:在 sync 上執行 async 函數。
- spawn:平行執行 async 函數。
- spawn_blocking:在非同步函數裡面,為一個高耗時且同步 (blocking) 的函數另闢新執行緒 (thread)。
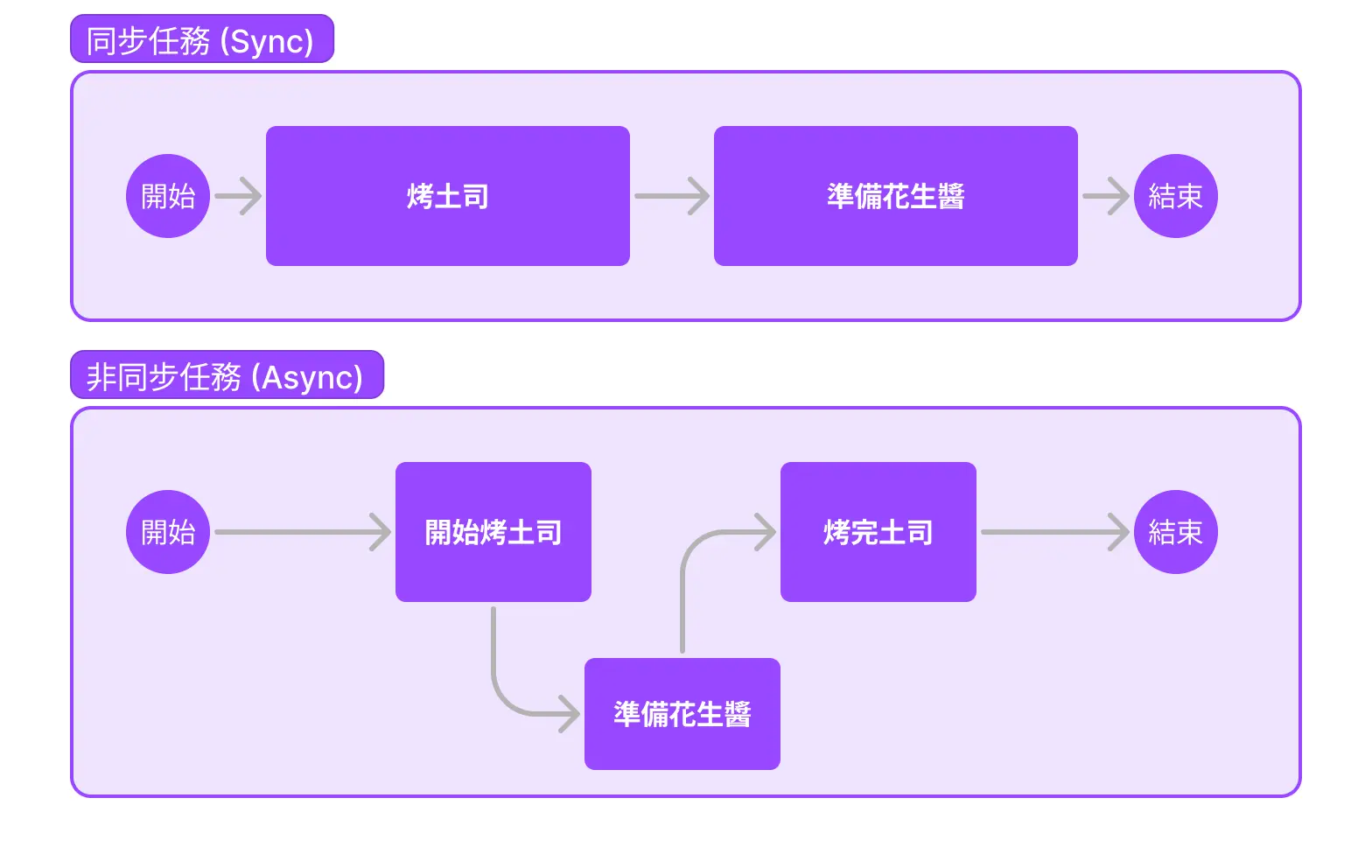
同步 (Synchronous) 跟非同步 (Asynchoronous)
「同步」就是整個程式等一件事情完成(blocking,堵塞)。「非同步」則是一件事情還沒完成,可以做其他不衝突的事情。
就以早餐來說,「同步」就像是等吐司烤完之後,才去準備花生醬(每件任務循序漸進地執行);「非同步」就像是吐司正在烤的時候,就先準備花生醬(每件任務並行地執行)。
並行 (Concurrency) 與平行 (Parallelism)
剛才有提到「吐司正在烤的時候,就先準備花生醬」是個 並行 行為。
並行 就是指程式架構,任務可以互不相關執行的特性。我們可以稱「吐司正在烤」和「準備花生醬」是個獨立任務,而我們可以 並行 地進行這些任務。
說到並行,那什麼是 平行 呢?
假如你媽也想幫你一起做早餐,而你負責「烤土司、準備醬料」,而你媽負責「煎蛋、擺盤」。你做自己的任務、而你媽做自己的任務——這就是 平行。
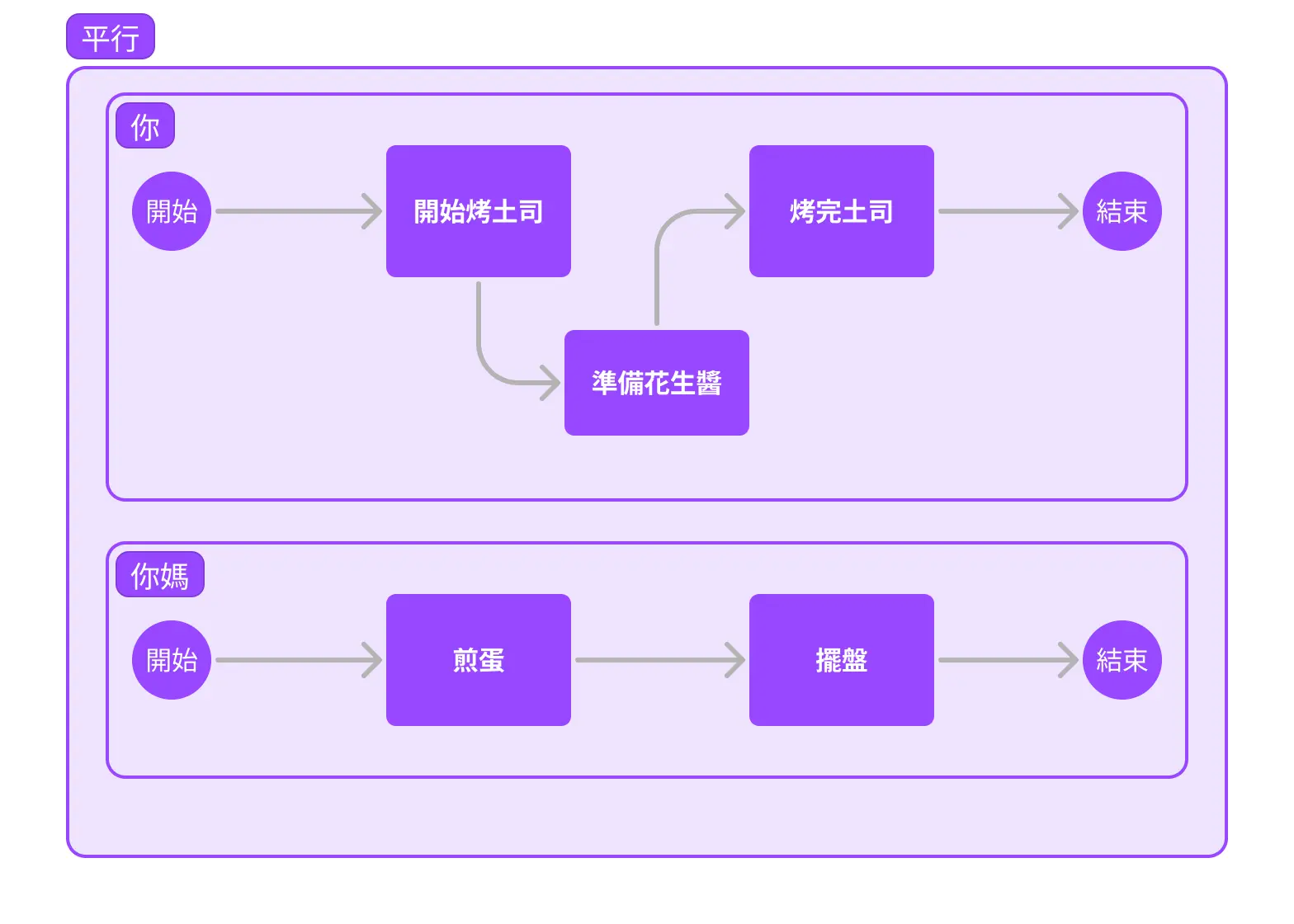
回到電腦的例子上。我們可以把「你」和「你媽」比擬為 CPU 核心 (core) ,分配給你和你媽的一大堆獨立任務叫做 執行緒 (thread) 。並行 就是工作單元自己用非同步的方式處理任務;平行 就是分配其他工作單元處理任務。
進階閱讀:執行緒池 (thread pool)
你電腦的核心是有限的。就以 Apple M1 這顆 CPU 來說,最多也就只有 8 個核心。那要怎麼高效的把一大堆執行緒,都分配到這些 CPU 上呢?
我們通常把這個「分配」叫做調度 (scheduling,排程)。首先,最簡單的做法就是自己跟系統開執行緒(通常我們把這種執行緒叫做 OS thread):
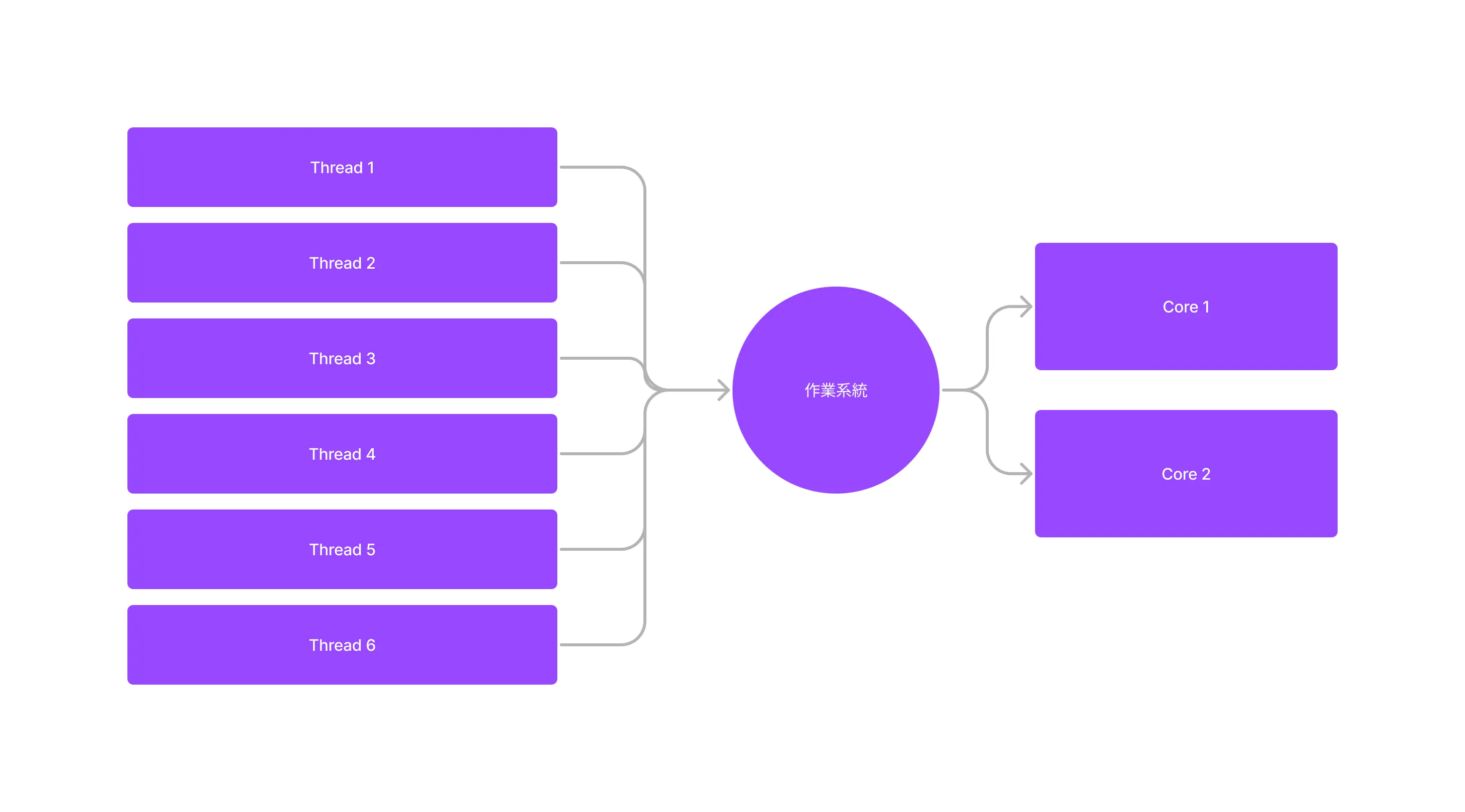
在 Rust 裡面,使用 OS thread 是非常簡單的:
let handle = std::thread::spawn(|| {
/* 你的同步作業 */
});
這樣的好處是不需要在程式裡面包一個調度器,但缺點是執行緒的 spawn 生成(把任務分配給家人)和 destroy 銷毀(告訴家人不用繼續執行任務)都得找你的作業系統(管家)操作。那如果我們可以自己調度,是不是就能減少找作業系統(管家)的開銷,甚至是做到更多更高效的事情(比如在一個執行緒裡面執行數個並行任務)?
首先,我們需要先跟管家說「我需要 N 個可以分配家人任務的執行緒,」然後把這些執行緒都放進去我們的 thread pool。接下來程式需要 thread 執行任務,就請 thread pool 分配。而我們從 thread pool 分配到的執行緒,就是 green thread。
用文字描述太混亂,直接用圖解吧:
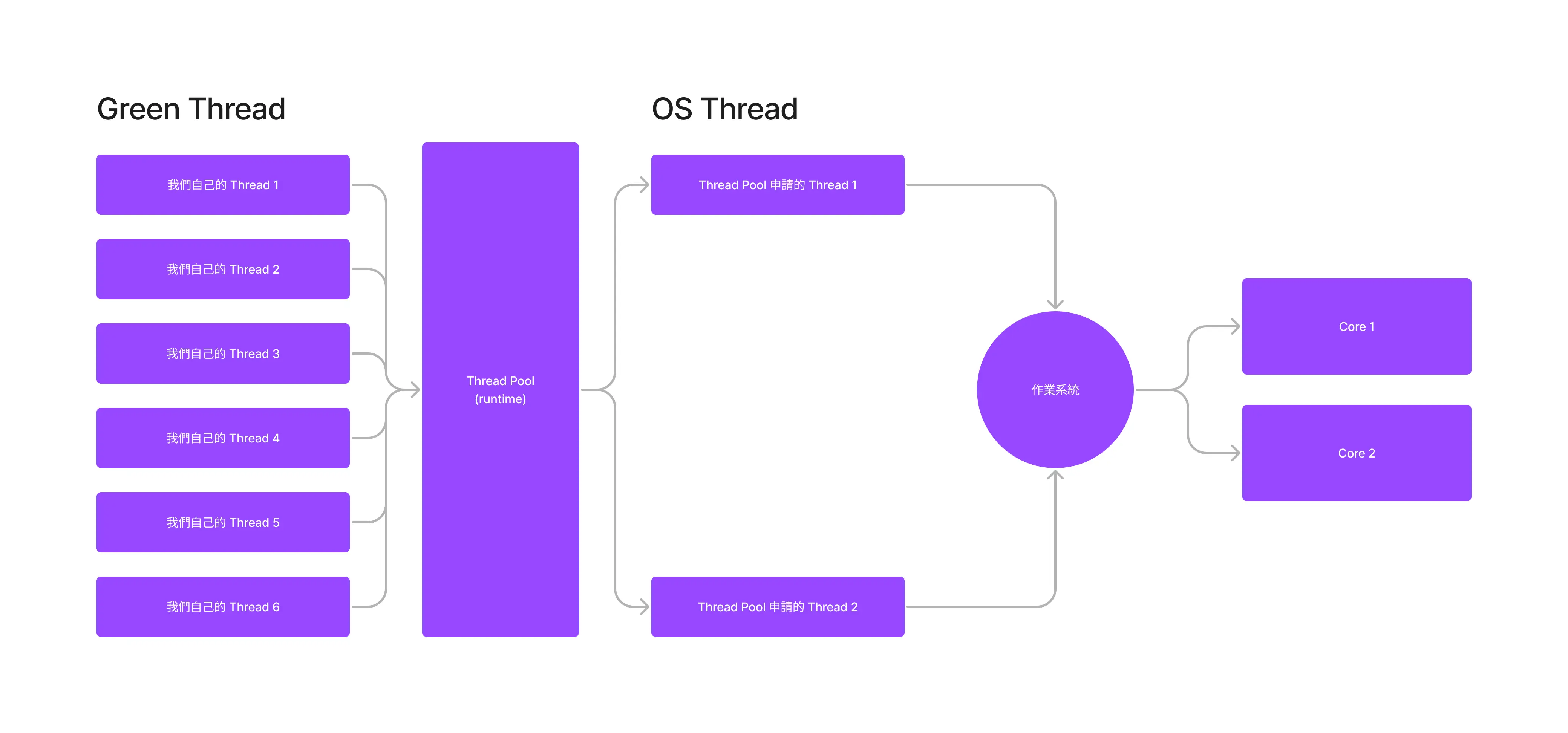
但假如每個 threads 裡面都是會堵住程式的任務 (blocking),那 Thread Pool 裡面的 OS Thread 就得等這些任務完成,最後反而沒有達到預期的高效分配。因此,如果 threads 裡面是完全 sync 的任務,就 沒有必要用上 thread pool,讓 OS 分配即可。
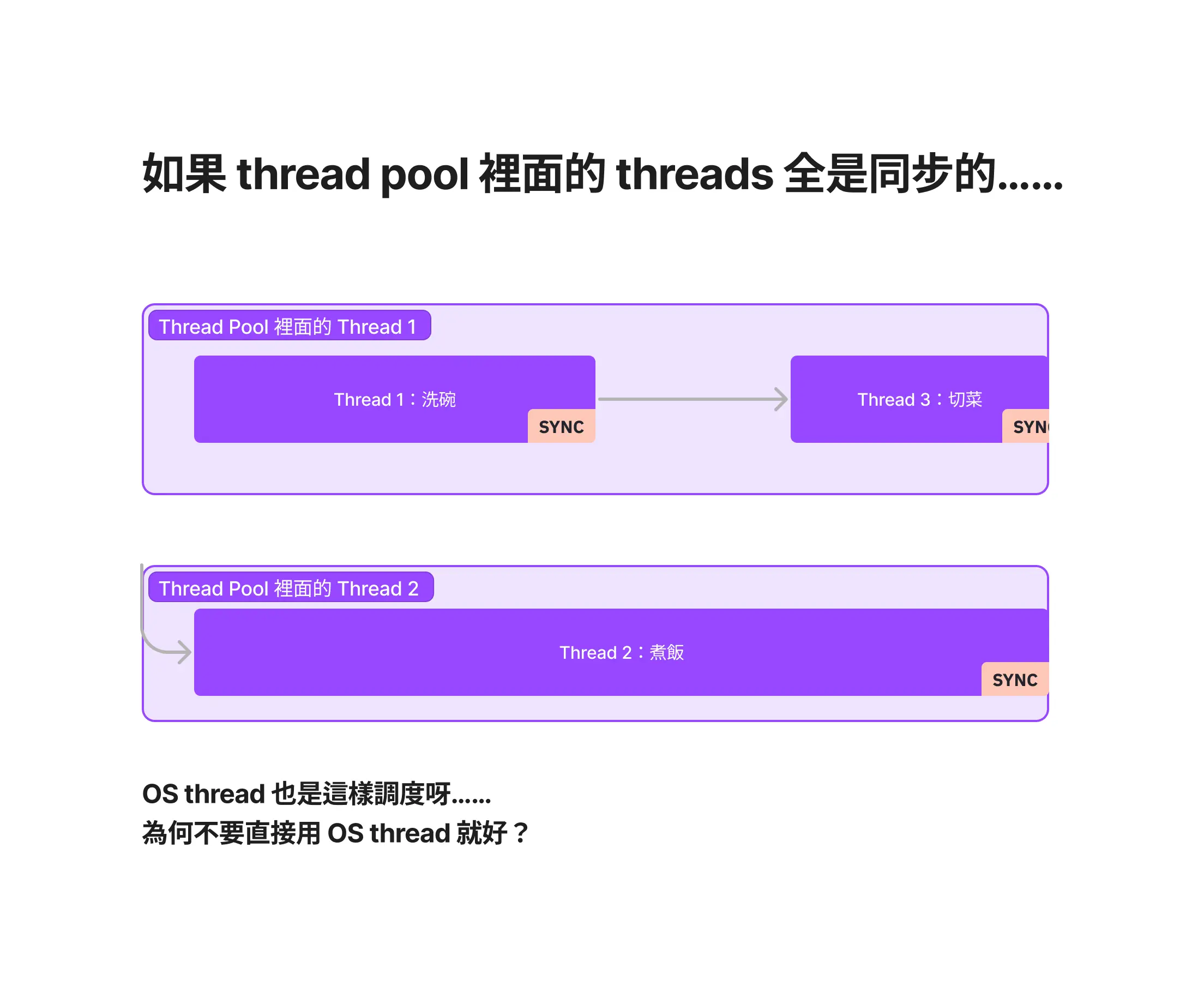
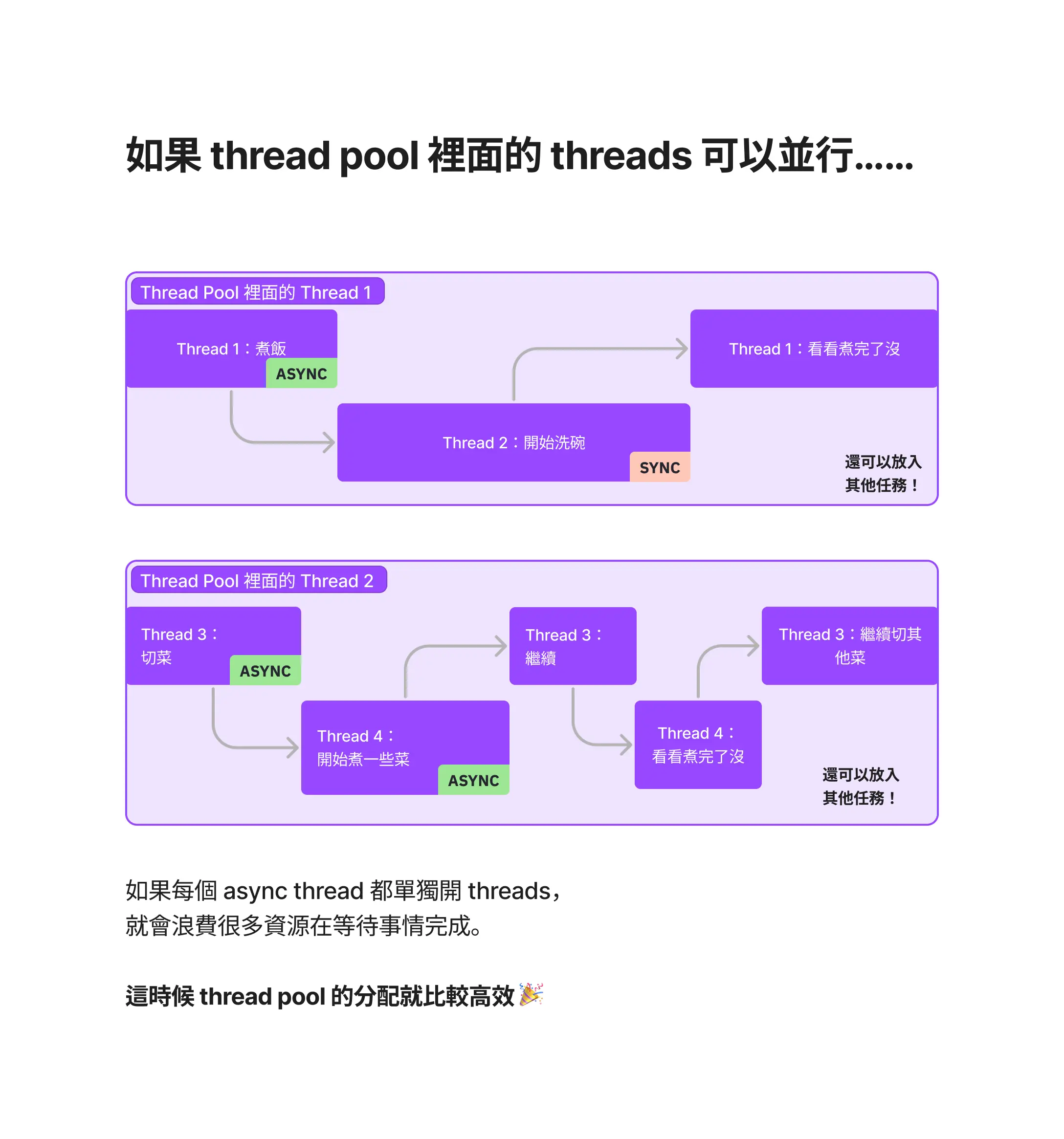
反之,如果 threads 裡面的任務可以並行,因為一個 thread 可以並行執行多個任務,thread pool 的安排就會顯得比 OS threads 高效許多:
進階閱讀:Future 與 Executor
對底層比較沒興趣?可以先看 Async 函數、區塊和 await。
基礎理論結束,拉回「任務」和 Rust 本身。你或許會很好奇「怎麼讓 Rust 知道一個任務是否完成?」
這裡就要提到 Rust 的 Future 了。Rust 的 Future 就是一個可並行任務的抽象表示。而 Executor 就是負責輪詢 (polling) Futures 的程式。把我們之前的「非同步」圖解用 Executor 的視角描繪出來:
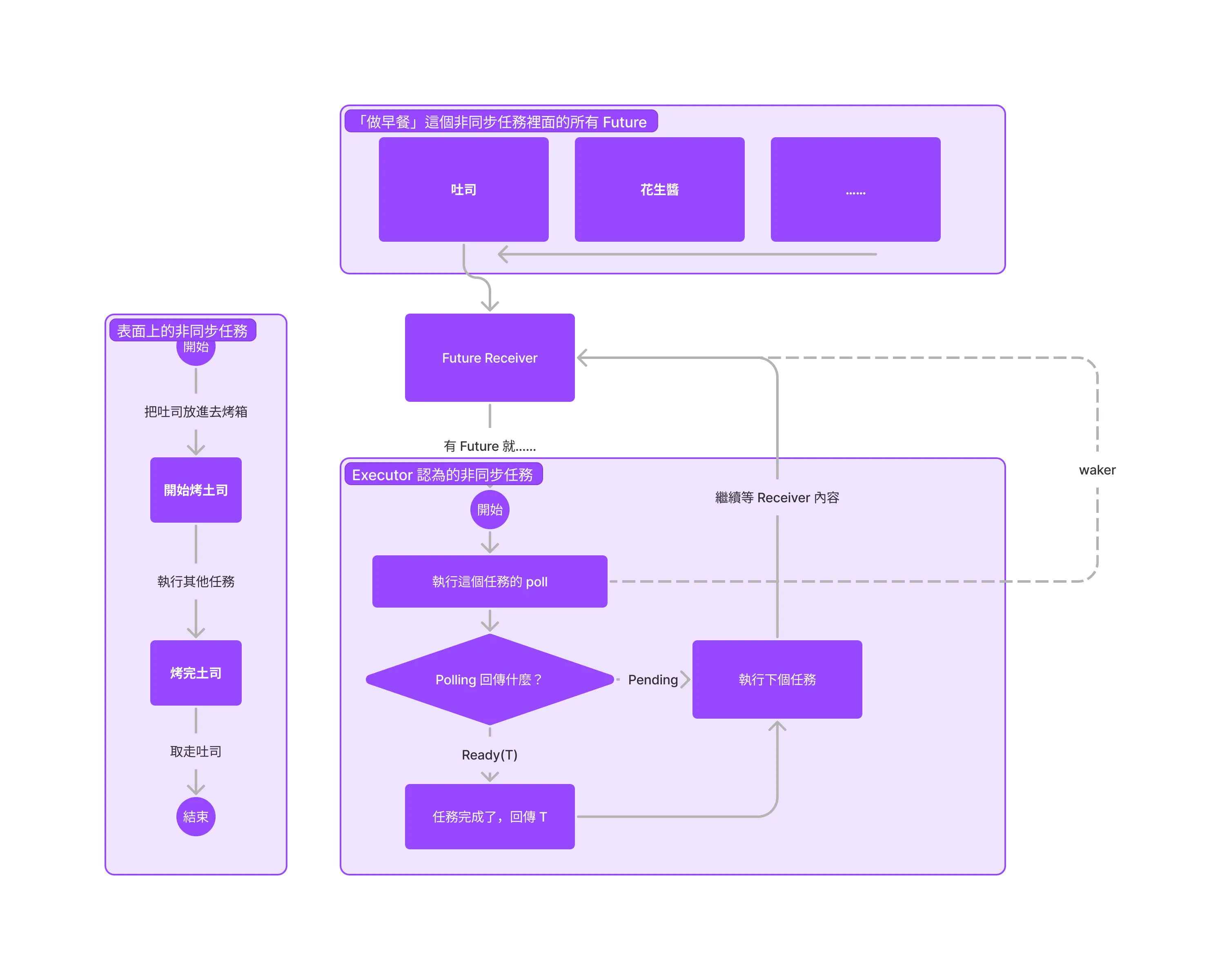
用文字表達:
- Executor 會從 Future Receiver 抓出一個 Future。
- Executor 執行這個任務的
poll(),並觀察其回應。 - 如果是
Poll::Pending(處理中),就繼續處理下個任務。 - 如果是
Poll::Ready(T)(已完成,回傳值是 T),則將回傳值交給需求方。
但這個文字流程有個問題:poll() 只會執行一次嗎?如果會執行數次,那 poll() 下次會在什麼時候執行?這裡就得提到 Rust 的 waker 機制了。每一次 poll(),Executor 都會給這個任務一個 context。裡面有一個 waker,可以用來提醒 Executor「可以執行 poll() 了。」
如果對這方面有興趣的話,可以參考 https://weihanglo.tw/async-book/02_execution/03_wakeups.html。另外 Future 還有很多很多的知識點(
Pin等等),礙於篇幅就先擱置。
延伸閱讀:Polling 等各種方式的優劣
Polling(輪詢),用程式寫出來是像這樣的:
loop {
let status = task.poll();
if let Polling::Ready(value) = status {
return value;
}
continue;
}
這樣有什麼問題?首先非同步任務通常要一段時間才會完成,一直 poll() 不會加快執行速度。如果真這樣寫,會浪費很多 CPU 時間在沒必要的 poll() 上。另外,loop {} 是個 blocking 同步函數,這樣子寫,下一個 Future 是執行不了的。
那換另一種方式呢?
let (tx, rx) = std::sync::mpsc::channel();
let mut return_values = vec![];
for task in rx {
let status = task.poll();
if let Polling::Ready(value) = status {
// 儲存回傳值,不再排程。
return_values.push(value);
} else {
// 繼續排程。
tx.send(task);
}
}
其實這就相當於在 poll() 階段回傳 Poll::Pending 前呼叫 wake_by_ref()——這個方法解決了 loop {} 的問題,但還是沒能解決「沒必要 poll() 的問題。」
倘若如果我們可以等到作業完成,再執行 wake() 呢?要這麼做,我們就得先知道「工作什麼時候才完成?」如果任務是用 callback 或 event 告知任務狀態的,那就是在收到 event、或 callback 觸發進行呼叫。
延伸閱讀:https://weihanglo.tw/async-book/02_execution/05_io.html
async 函數、區塊和 await
上面介紹了很多 Rust 中 Future 與 Executor 的理論基礎,但實務上沒有這麼麻煩。事實上在 Rust 中,用 async 函數和 block 是非常直覺的。
就以上面的 早餐例子 來說,我們可以把它先改寫成這樣:
async fn make_breakfast() -> Toast {
let toast = bake_toast().await;
let butter = prepare_peanut_butter().await;
toast.apply(butter);
toast
}
你或許會很疑惑他跟下面這個版本有什麼差異:
fn make_breakfast() -> Toast {
let toast = bake_toast();
let butter = prepare_peanut_butter();
toast.apply(butter);
toast
}
首先,雖然整體上「做早餐」還是循序執行的(先烤完吐司、才準備花生醬),但做早餐這件事情因為已經是非同步的了,所以你可以在做早餐的時候做其他事情:
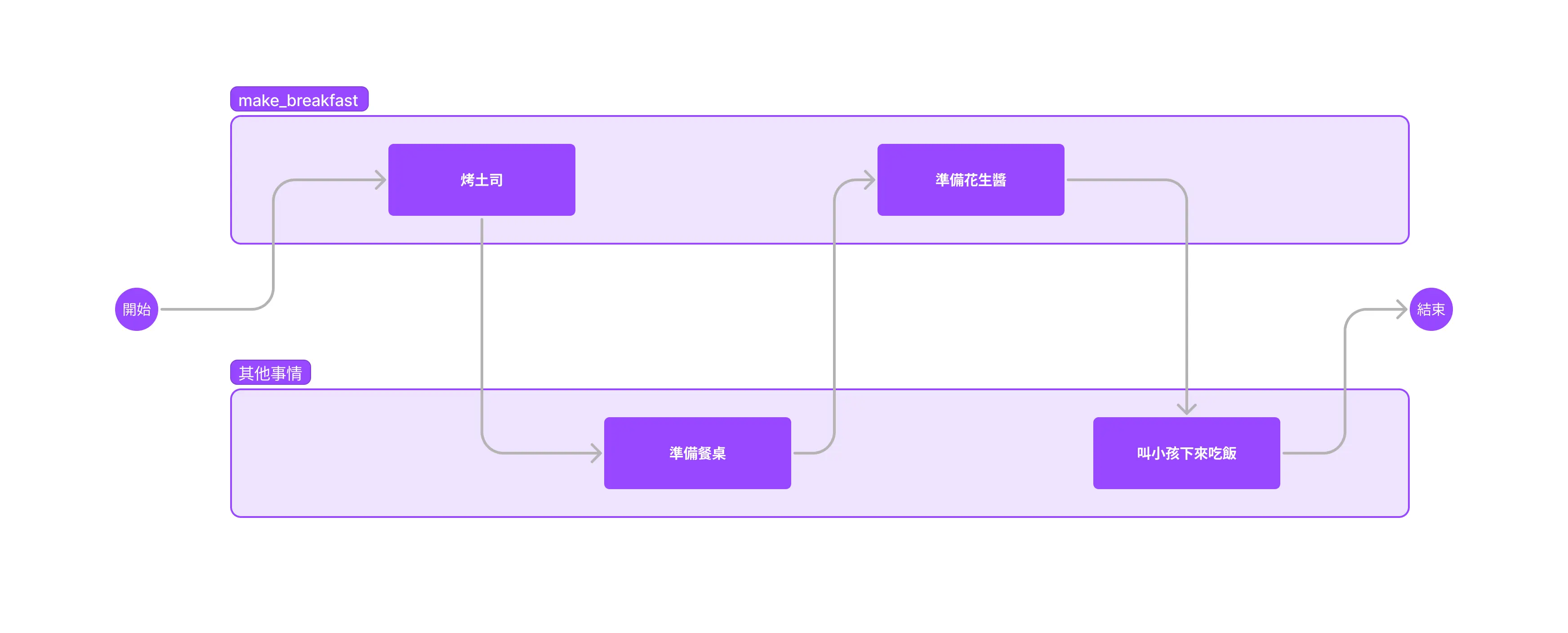
後者的話就是純 Sync,明顯是比前者低效的:
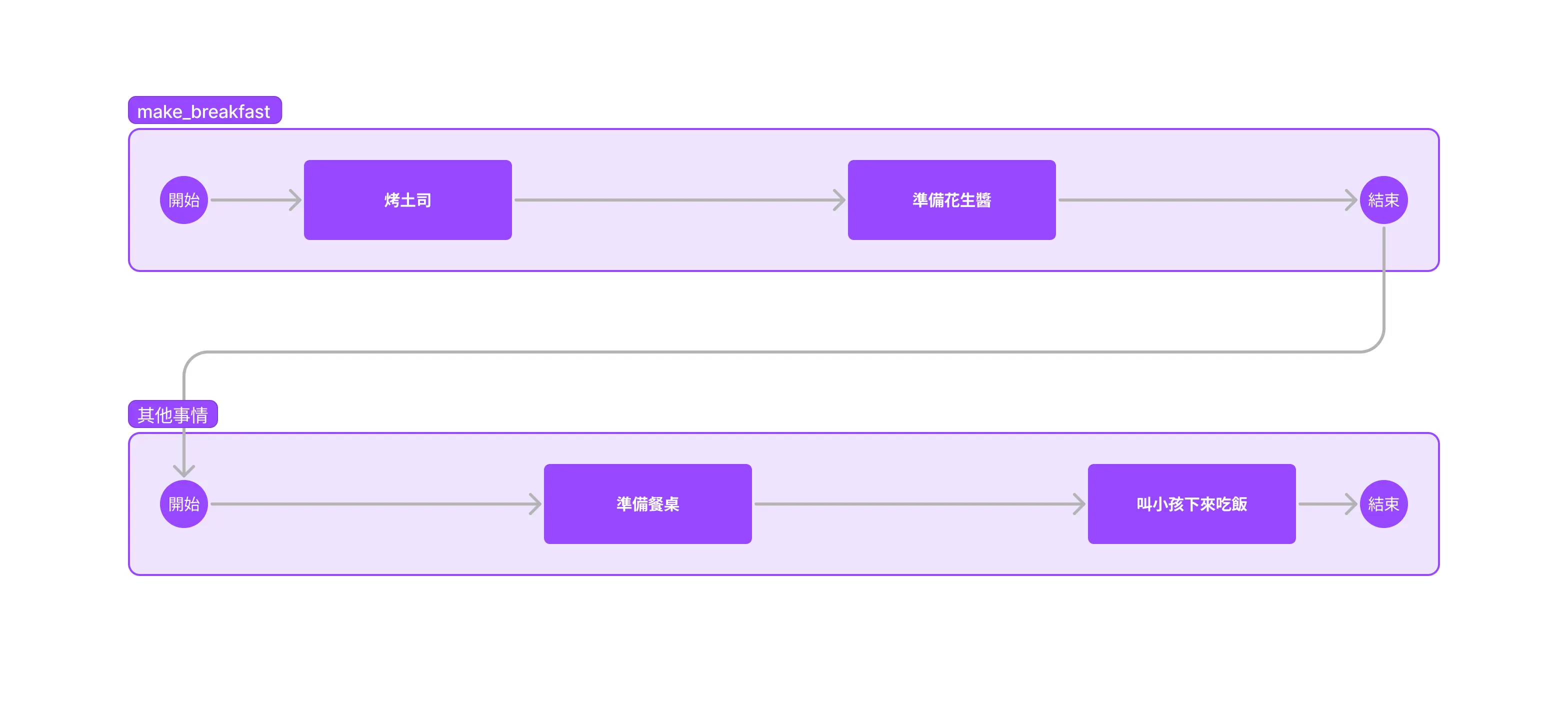
對照圖片,或許你發現到 .await 剛好就是「任務切換點」。.await 之後,你可以去做其他事情(而不是空等)。等到烤箱聲音響了之後 (wake()) 之後再回來做剩下的事情。所以整體上 async 函數是比較高效的,但我們要怎麼讓整個任務更高效呢(在 async 裡面一次性執行更多任務?)
在 async 函數裡面並行執行數個任務 (futures)
剛才提到我們希望在一個 async 裡面一次性執行數個任務。這裡我們可以借助 tokio 的 join!() 工具巨集,表示「我希望這兩個任務同時操作」,就像是把這兩個任務融合為一了:
async fn make_breakfast() -> Toast {
let (toast, butter) = tokio::join!(
// 要注意這裡不需要 .await,
// await 的事情 `join!()` 會處理。
bake_toast(),
prepare_peanut_butter()
);
toast.apply(butter);
toast
}
這樣 make_breakfast 裡面就是高效的模式了:
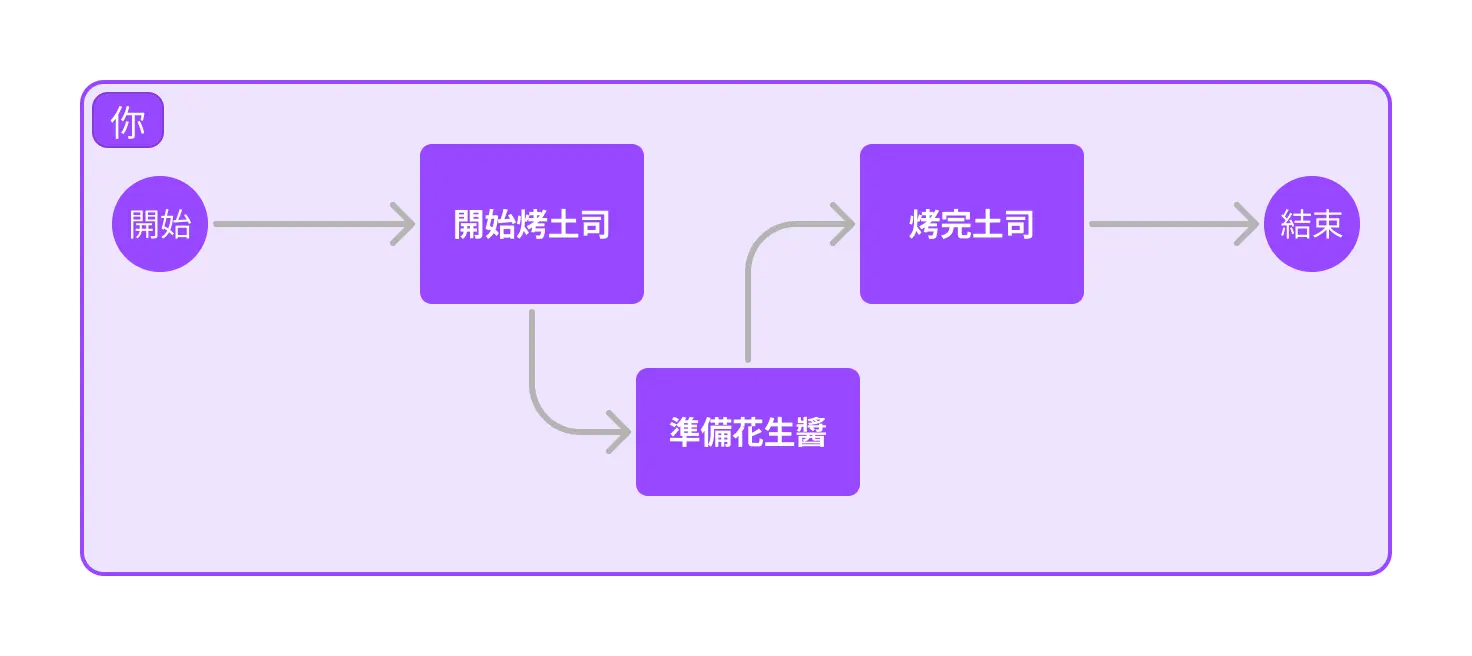
那換一種現實中也常遇到的例子:你希望早餐可以在小孩上學前做完,如果沒做完就不要繼續做了。所以我們想要設置一個計時器,如果計時到了還沒做完就直接取消;反之就繼續做:
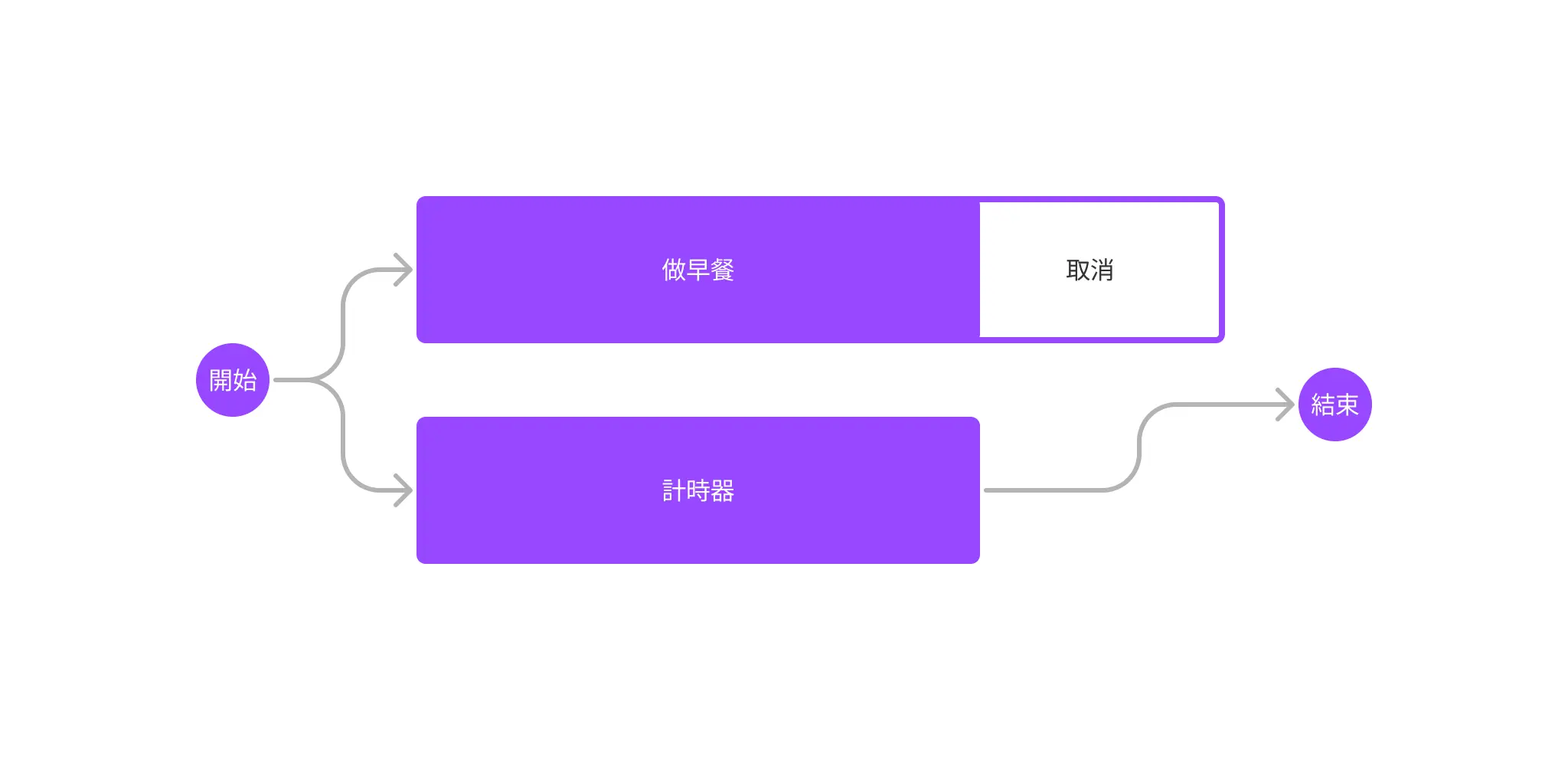
這種情況就可以用 tokio::select!()——同時等「做早餐」跟「計時器」,回傳完成速度最快的任務(分支),而取消剩下沒做完的任務(分支):
// Option 包含「有」或「沒有」兩種可能。如果計時器到了,
// 吐司還沒完成,那就沒有早餐;反之,就有早餐。
async fn make_breakfast_with_timer() -> Option<Toast> {
tokio::select! {
// 如果早餐先完成,那就有早餐。
toast = make_breakfast() => Some(toast),
// 如果時間先到,那就沒早餐。
_ = timer() => None,
}
}
/// 一個設定在 30 分鐘的計時器
async fn timer() {
tokio::time::sleep(
std::time::Duration::from_secs(30 /* min */ * 60 /* sec */)
).await
}
async fn make_breakfast() -> Toast {
let (toast, butter) = tokio::join!(
bake_toast(),
prepare_peanut_butter()
);
toast.apply(butter);
toast
}
如果你對這方面很有興趣,可以看看 https://weihanglo.tw/async-book/06_multiple_futures/01_chapter.html。
延伸閱讀:await 只能在 async function 裡面執行
要注意的,是 .await 只能在 async block 或 async function 裡面使用。也就是說,你不能在同步函數(包括 main())裡面呼叫非同步函數:
fn main() {
// 會編譯錯誤!
let file_content = make_breakfast().await;
// 還是不行 😄
let file_content = async {
make_breakfast().await
}.await; /* async block 也需要 await */
}
既然每個呼叫者都必須是 async 的,那是誰呼叫第一個 async 函數呢? 這就得提到 Async Runtime 了。
進階閱讀:從 Future 看 async 和 await
但這裡面的 async 和 await 分別代表什麼意義呢?async fn 其實展開來看,就是一個回傳 Future 的函數:
struct ReadFileFuture { ... }
impl Future for ReadFileFuture {
type Output = String;
fn poll(...) { ... }
}
fn read_file(path: &Path) -> ReadFileFuture {}
而 await 的大致意思就是「沒完成就說整個函數沒完成;完成就繼續」:
// 把這個函數的 context 轉交給 read_to_string
let content_status = tokio::fs::read_to_string(path).poll(cx);
let content = match content_status {
// 如果這個 feature 沒完成,就剩下的 async 也就無法繼續。
Poll::Pending => return Poll::Pending,
// 反之,把值拿回來
Poll::Ready(c) => c,
}
實際上這部分還有許多地方需要考慮:包括要怎麼在下次呼叫 poll() 的時候,知道現在要繼續執行哪個 Future。更詳細的資訊可以參考 https://weihanglo.tw/async-book/02_execution/02_future.html。
Rust 的 async runtime
實務上你不需要自己寫一個 executor,而是使用現成的 async runtime(執行階段、執行時)。一個 async runtime 除了 executor 之外,還有提供很多功能(比如上文提及的 thread pool、工具巨集和函數,以及檔案讀寫、channel 等等常用功能的非同步對應方法)。
常見的 async runtime 有 tokio、async-std 和 smol,其中又以 tokio 和 async-std 為大宗。下文會以 tokio 作為介紹範例。
讓 main() 變成 async 函數的起源地
我們在〈延伸閱讀:await 只能在 async function 裡面執行〉裡面有提及「所有呼叫者必須都是 async function,」那 main() 呢?
還記得上文有提到「Futures 需要一個 executor 調度?」那 main() 原則上就是配置 runtime,讓 runtime 準備 executor 的地方:
fn main() {
// 設定多執行緒的 tokio runtime。
tokio::runtime::Builder::new_multi_thread()
// 啟用所有功能。
.enable_all()
// 建構 runtime。
.build()
// 如果 runtime 建構失敗就停住整個程式。
.unwrap()
// async 函數的起源地——堵塞 (blocking),
// 讓整個 main() 等待這個 async 函數完成。
.block_on(async {
println!("Hello world");
})
// 然後程式就可以結束了。
}
不過其實不用這麼麻煩:tokio::main! 這個 屬性巨集 (attribute macro) 就能幫你寫好這方面的初始化了。你只要這樣就好:
#[tokio::main]
async fn main() {
println!("Hello, World!");
}
進階閱讀:讓一個任務 (Future) 變成一個綠色執行緒 (Green Thread)——spawn
還記得並行 (Concurrent) 跟平行 (Parallelism) 嗎?雖然大部分的情況下,在 單執行緒「並行」就已經很足夠快了。倘若這個任務耗時很長,你希望開另一條執行緒「平行」專門處理這個任務,那就可以用 spawn:
let handle = tokio::task::spawn(async {
/* 現在這裡面的東西,都在獨立的 thread 裡面跑了! */
});
tokio::task::spawn 雖然用起來很像建立 OS thread 的 std::thread::spawn,但 spawn 裡面不要放高耗時的同步函數——除非你樂見整個 runtime 被卡在一件任務上面(或者是直接把 runtime 搞死,直接 panic!)
那要怎麼在非同步函數裡面,開另一個 thread 跑同步函數呢?你可以用接下來會提到的 tokio::task::spawn_blocking。
在非同步函數裡面呼叫高耗時同步函數——spawn_blocking
除了開一個 std::thread::spawn OS thread 跑這種函數之外,你也可以用
tokio::task::spawn_blocking 開一個 可以 await 的同步 blocking 堵塞函數。
let _this_returns_42 = tokio::task::spawn_blocking(|| {
for i in 0..114514 {
for j in 0..1919810 {}
}
42
}).await;
這樣子跑高耗時的函數之時,照樣可以執行其他不用堵塞的任務。同理,你也可以把這個套進去 join! 並行完成,可是 這樣建立出的 thread 是取消不了的——不只是單純的 select!,還包含 .abort() 。因此還是盡量選擇並善用非同步函數。想深入了解 sync 函數與 async 函數橋接的資訊,可以參考 https://tokio.rs/tokio/topics/bridging。
結語
基本上把這則 Twitter 推文想要知道的大部分知識點都講了。礙於個人能力不足,或許講得不夠清晰或不甚明確,也十分歡迎各路專家指正 QQ
另外這篇文章花了我 7hr 來寫,如果覺得有用的話,歡迎把這篇文章分享給更多對 async 以及 Rust 非同步程式有興趣的人 owo 謝謝 🙏
另外也可以 follow 我的 GitHub 支持我的 OSS 工作 ouo
參考文獻
- https://medium.com/erens-tech-book/%E7%90%86%E8%A7%A3-process-thread-94a40721b492
- https://hackmd.io/@sysprog/concurrency/https%3A%2F%2Fhackmd.io%2F%40sysprog%2FS1AMIFt0D#Concurrency-%E4%B8%A6%E8%A1%8C-vs-Parallelism-%E5%B9%B3%E8%A1%8C
- https://weihanglo.tw/async-book/02_execution/02_future.html
- https://en.wikipedia.org/wiki/Scheduling_(computing)
- https://zh.wikipedia.org/wiki/绿色线程
- https://doc.rust-lang.org/std/future/trait.Future.html
- and more, a lot. Thanks to these authors ❤️